Word cloud
Portafolio
Dataviz
Resumen
Una visualización de datos correcta puede expresar de forma resumida y clara gran cantidad de información, ayudando a interpretar y asimilar la información más facilmente.
Word cloud de las primeras diez mil palabras del Quijote.
INCLUIR LINK NLP
Incluir link al repositorio de NLP
Librerías específicas.
(Funcional paquete ‘wordcloud’)[https://cran.r-project.org/web/packages/wordcloud/wordcloud.pdf] (Más ejemplos de ggwordcloud)https://cran.r-project.org/web/packages/ggwordcloud/vignettes/ggwordcloud.html
Datos.
Fuente: https://www.gutenberg.org/cache/epub/2000/pg2000.txt
Código.
Código
# Leo el Quijote
quijote <- readLines("../data/quijote.txt", encoding = "UTF-8")
# Concateno todas las líneas en una sola cadena
quijote <- paste(quijote, collapse = " ")
# Convierto el Quijote a minúsculas, elimino caracteres especiales
quijote <- tolower(quijote)
quijote <- str_replace_all(quijote, "[^a-záéíóúüñ]", " ")
# Dividir el texto en palabras y eliminar stop words
quijote_words <- unlist(strsplit(quijote, "\\s+"))
quijote_words <- quijote_words[!quijote_words %in% tm::stopwords("spanish")] # análogo: quijote_words <- quijote_words[!quijote_words %in% stopwords::stopwords("spanish")]
quijote_words <- quijote_words[!quijote_words %in% tm::stopwords("spanish")]
# Filtrar las palabras vacías (espacios en blanco) y obtener las primeras 1000 palabras
quijote_words <- quijote_words[quijote_words != ""]
first_1000_words <- quijote_words[1:10000]Código
wordcloud(words = first_1000_words, min.freq = 10, colors = brewer.pal(8, "Dark2"))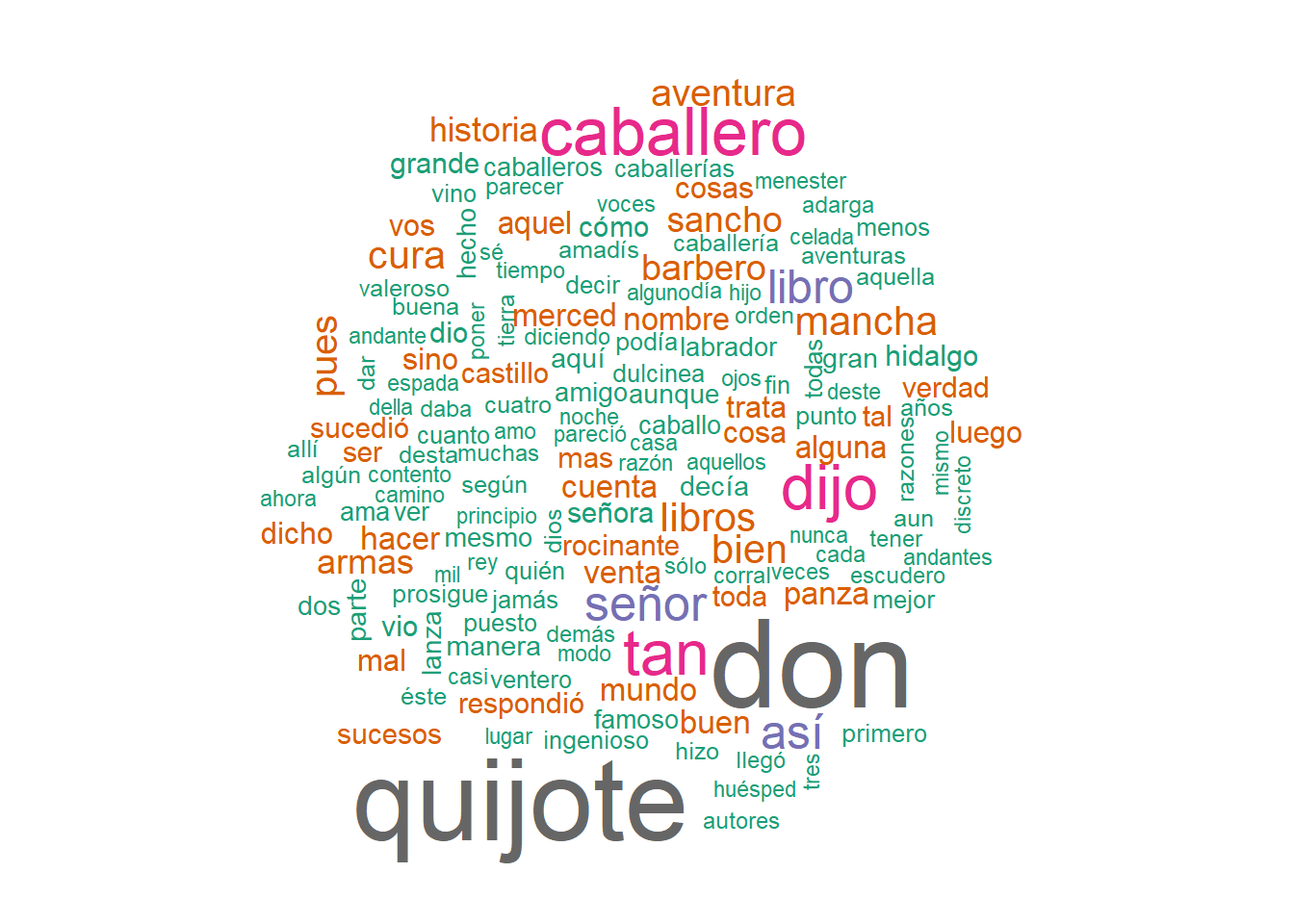
Código
# first_1000_words |> table() |> as.data.frame() |>
# ggplot(aes(label = first_1000_words, size = Freq)) +
# geom_text_wordcloud() +
# scale_size_area(max_size = 30) +
# theme_minimal()Código
data("love_words_small")